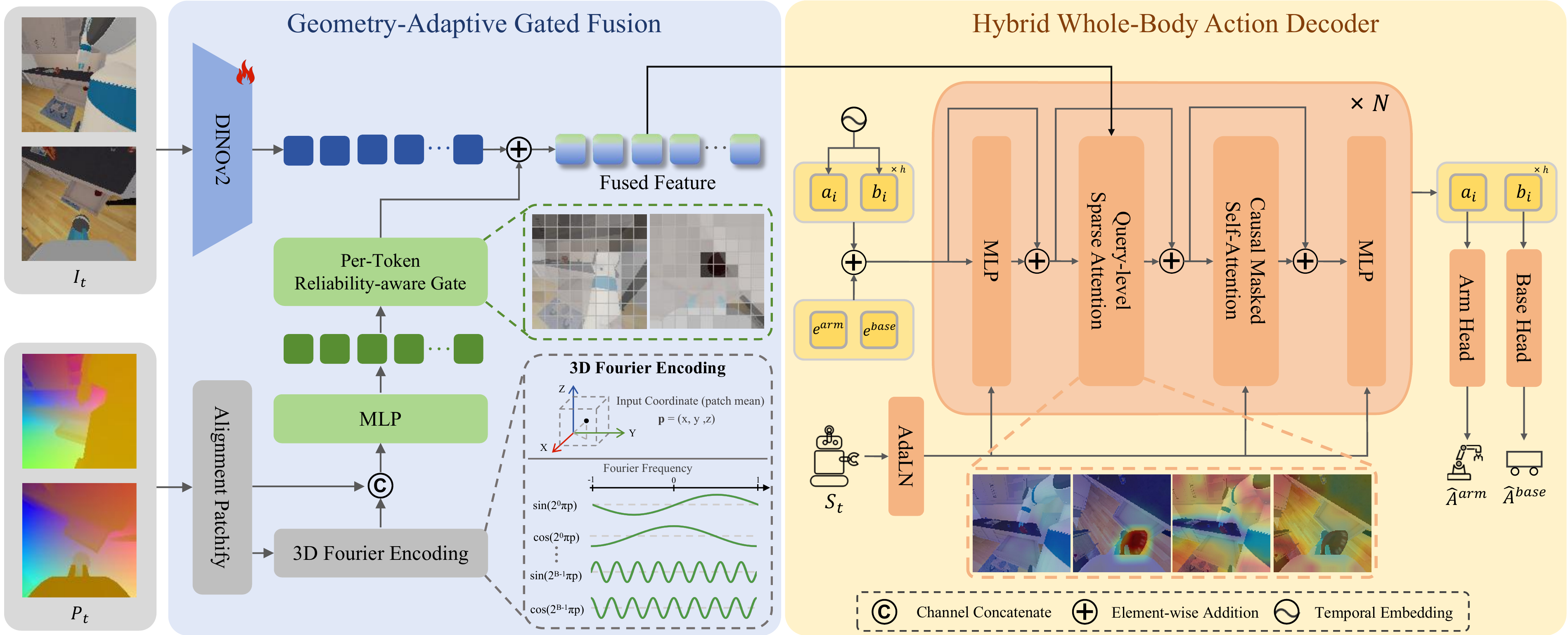
Abstract
Whole-body mobile manipulation requires coordinating mobile base and manipulator under shifting viewpoints, posing challenges in geometric perception and action generation. Current policies either rely on 2D features or sparse 3D representations that lack dense spatial structure, and typically encode arm and base within one action vector that ignores their distinct control demands. Moreover, existing dense fusion strategies risk corrupting pretrained representations under noisy depth while incurring heavy computational overhead. We present GeoHAT, an end-to-end diffusion-based framework built on a simple principle: geometry should be injected only where reliable and attended to only where needed. GeoHAT employs a lightweight Fourier spatial encoder that maps dense per-pixel 3D coordinates into geometric tokens without an additional 3D vision backbone. These tokens are then selectively injected into vision foundation model features through per-token gated fusion modulated by depth validity, preserving the semantic prior while enriching spatial understanding. For action generation, a Hybrid Whole-Body Action Decoder decomposes arm and base into distinct subspaces and lets each action modality attend to its task-relevant visual context through sparse cross-attention, while causal temporal modeling captures intra-timestep coordination and inter-timestep dependencies. Experiments on the ManiSkill-HAB simulation benchmark demonstrate that GeoHAT achieves a 79.3% mean success rate, surpassing the strongest baseline by 23.7%. Furthermore, real-world experiments on diverse tasks also confirm consistent improvements over all baselines.